
Post-mortem sur les récents problèmes techniques
Serveur, Service DoH et raccourcisseur de liens
Bonjour,
Ces dernières semaines, nous avons encaissé des dysfonctionnements techniques d’une certaine ampleur causant plusieurs pannes de nos services.
🔗Panne serveur
27 septembre 2019 à 00h32 : Le serveur sur lequel était hébergé notre VPS s’éteint.
En conséquence, tous nos services et notre site web se retrouvent hors-ligne.
00h40 : Nous prenons conscience de ce problème par chance, faute de manque de monitoring.
Nous tentons d’abord de redémarrer le serveur depuis l’interface de notre hébergeur, Proxgroup. Mais puisque toute la node qui l’héberge est hors-ligne, l’opération échoue.
01h00 : Nous avons publié une annonce de service sur Mastodon.
01h17 : Nous créons un ticket sur l’interface de Proxgroup, au niveau d’urgence “critique”. Nous craignons en avoir pour la nuit voire le week-end
01h29 : Comme par miracle, l’un des membres du staff de Proxgroup nous répond 12 minutes après, en ayant constaté le problème et redémarré le serveur.
Notre serveur a donc été redémarré à 01h26, avec tous ses services.
01h40 : Après avoir vérifié plus amplement que tout est bien fonctionnel à nouveau, nous publions une deuxième annonce de service sur Mastodon.
Selon leur page de statut, il s’agirait d’une panne réseau. En tout cas, il s’agit du premier incident de la sorte depuis que nous sommes chez eux et ils ont réagi en un temps record (12 minutes à 1h30 du matin, quand même). Un grand merci à eux !
🔗“Attaque” sur le proxy DoH
Nous avons constaté une montée en charge phénoménale de notre proxy DoH à partir du 24 septembre 2019 à 09h10. Nous recevions peu de requêtes, mais provenant d’un très grand nombre d’IPs. Les requêtes étaient étrangement formées et semblaient utiliser des implémentations obsolètes du DoH ou même des extensions qui ne semblent pas documentées.
Ce “spam” générait une quantité assez importante de trafic et a eu pour conséquence quasiment immédiate de bannir notre proxy des résolveurs de FDN, bloquant l’accès au service pour tous les utilisateurs.
Nous n’avons malheureusement pas mis en place une solution de monitoring et de protection suffisamment efficace pour couvrir ce vecteur d’attaque. Nos ratelimits s’appliquent par IP pour ne pas dégrader la qualité du service pour les autres clients.
Notre serveur a donc continué à se faire spammer durant 24 heures. Le trafic a augmenté de manière exponentielle, mais nos serveurs ont tenu bon. Cependant, aucune de ces requêtes n’a abouti car nous étions bannis par FDN.
Durant ces 24 heures, nous sommes passés de 40-80 IPs uniques par jour utilisant nos services à 20 000 IPs uniques, ainsi que 565 000 requêtes provenant de ces IPs contre environ 60 000 habituellement, soit environ 10 fois notre trafic habituel.
Le 26 septembre 2019 vers minuit, nous nous sommes rendus compte de l’attaque et avons immédiatement stoppé le service.
Il nous a fallu plusieurs heures pour développer des solutions de protection, qui ont consisté à bloquer ces “requêtes malformées”.
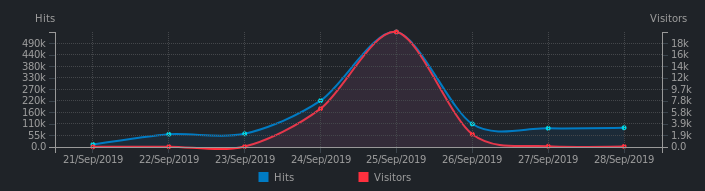 Screenshot : Requêtes traitées par le service DoH.
Screenshot : Requêtes traitées par le service DoH.
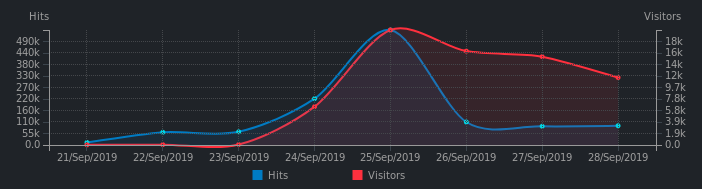 Screenshot 2 : Requêtes traitées par le service DoH, en incluant les visiteurs uniques dont l’IP est immédiatement bannie sans donner suite à la requête.
Screenshot 2 : Requêtes traitées par le service DoH, en incluant les visiteurs uniques dont l’IP est immédiatement bannie sans donner suite à la requête.
Nous avons demandé conseil à Stéphane Bortzmeyer et FDN pour avoir plus de détails sur la manière dont nous devons gérer la situation.
Entre-temps, nous avons repéré un commit sur le dépôt de la liste des résolveurs de dnscrypt-proxy, un logiciel assez connu qui permet de chiffrer des requêtes DNS.
La date du commit concorde : l’ajout de notre proxy à cette liste est sans aucun doute l’élément déclencheur qui a entraîné cette gargantuesque montée en charge. Cela explique pourquoi autant d’IPs nous ont attaquées en même temps et pourquoi elles n’étaient pas dans les blacklists de spam connues : elles étaient légitimes.
Ce commit a été rédigé par jedisct1, qui est notamment le développeur de doh-proxy et edgedns, logiciels que nous utilisons pour faire tourner nos services, et contient plusieurs erreurs :
- Il mentionne que nous sommes l’association FDN (faux !) ;
- Il mentionne que nous utilisons le DNS public de Google (encore plus faux !!).
Nous l’avons donc contacté pour démentir ces faits et, constatant que notre infrastructure n’allait pas tenir le coup si nous restions sur cette liste, nous avons émis une pull request sur son dépôt pour retirer notre proxy des résolveurs DNSCrypt.
Depuis, nous avons optimisé notre configuration pour résister plus efficacement contre ce flux de requêtes ; la mise à jour de la liste devrait se propager peu à peu et soulager notre service.
Entre-autres, nous avons paramétré notre cache DNS pour qu’il garde en mémoire ses entrées pendant 30 minutes minimum, sans tenir compte des entrées DNS dont le TTL est inférieur à 30 minutes ; cela devrait soulager les résolveurs de FDN pour un temps.
🔗Raccourcisseur de liens
Nous avons dû faire face à une utilisation malveillante de notre service, nous l’avons donc remplacé.
Voir notre article sur rs-short pour plus de détails.
🔗Leçons tirées
- Nous devons installer des solutions de monitoring plus solides afin de voir venir ce genre de catastrophes et agir promptement.
- En gagnant de la visibilité, nous nous exposons à des montées en charge rapides et des attaques plus nombreuses et plus complexes à gérer.
- Il est peu concevable d’héberger un service en libre accès et de partir du principe que “nous serons trop petits pour subir quoi que ce soit”.
- Il ne sert à rien de paniquer comme un dingue lorsque les services sont down. Il faut respirer, là, du calme, tout va bien, on va s’en sortir, ce n’est pas grave, allez, on réfléchit ensemble et on y va.
On a encore du progrès à faire. En espérant ne pas décevoir vos attentes. :D
À bientôt,
~ N&B