
Ticket d’or pour visiter nos fabriques à services
Technique, partie 3 : Les rouages de nos outils duplicables à souhait
Cet article est le dernier de la série consacré à la gestion informatique de La Contre-Voie ! La semaine prochaine, nous reprendrons notre ligne éditoriale habituelle :)
Après vous avoir présenté le matériel utilisé pour nos serveurs informatiques, puis le module d’authentification unifiée qui connecte nos services entre eux, il serait bien temps que nous vous présentions les logiciels qui font tourner nos nouveaux services !
En ce qui concerne nos services historiques, vous trouverez ici notre documentation technique qui rassemble toutes les instructions et informations utiles pour maintenir nos outils internes.
Nos nouveaux services « à la carte », quant à eux, ne sont pas encore documentés puisqu’ils ne sont pas encore officiellement sortis : ils sont utilisés pour nos accompagnements numériques expérimentaux et nous espérons les inaugurer officiellement d’ici mi-2025.
En attendant, dans ce présent article, nous vous donnons le ticket d’or pour visiter nos fabriques à services ! Celleux qui nous suivent pourront constater que nos méthodes ont sensiblement évolué par rapport à notre précédente infrastructure.
🔗C’est quoi, une fabrique à services ?
On parle aussi parfois de ferme, ou d’usine à services, ou encore d’un déploiement multi-sites ; nous définissons cela comme un ensemble de processus permettant de dupliquer un service sans effort, pour en héberger pour autant de personnes ou d’organisations que nécessaire en réduisant au maximum le coût et le temps passé sur le déploiement d’un nouveau clone.
Chacune de ces copies de ce service cloisonne les données et la configuration entre chaque organisation, mais partage les autres ressources : bases de données, caches, serveur HTTP, dossiers système… le but étant de mutualiser le plus de ressources possible.
Il arrive même que nous mutualisions l’instance d’un logiciel tout en maintenant le cloisonnement des données, auquel cas on appelle ça une configuration multitenant ! Mais ce n’est pas possible avec tous les logiciels que nous hébergeons.
Pour prendre l’exemple de WordPress : s’il nous faut héberger 20 organisations, ça nous nécessiterait initialement d’héberger 20 instances de WordPress différentes, ce qui implique de toutes les tenir à jour, les configurer individuellement, les superviser… et avoir les ressources (mémoire, CPU) suffisantes pour les héberger.
Nous verrons plus tard dans cet article comment nous pouvons techniquement héberger 20 organisations avec une seule instance de WordPress, sans compromis sur la performance ou la stabilité, et sans courir le risque que les 20 sites web soient indisponibles si l’unique instance tombe en panne !
Nous vous y présenterons également le double enjeu d’avoir des instances reproductibles à souhait, mais aussi d’y intégrer une authentification OpenID Connect pour connecter chacun de ces services à notre SSO.
🔗La gestion des données
Mais avant cela, il nous faut établir comment nous allons stocker les données des utilisateur·ices. C’est la première brique fondamentale pour créer une fabrique à services : si cette partie-là est bien pensée, le service sera facilement reproductible par la suite.
Actuellement, nous avons huit serveurs en production. Ces serveurs pourraient être amenés à se répartir des services à héberger. Nous pourrions aussi avoir besoin de rapidement basculer une instance d’un service sur un autre serveur.
Plus courant encore, nous pourrions vouloir séparer le stockage et le calcul sur des machines différentes : un groupe de machines avec beaucoup d’espace de stockage dont le rôle est de conserver les dossiers des données et de servir de base de données, et un autre groupe qui héberge les instances des logiciels et les autres programmes qui manipulent ces données.
L’enjeu est donc de réussir à rendre les données hébergées accessibles en réseau depuis un autre serveur et d’éviter autant que possible de stocker des données en local.
🔗La base de données et le cache
Pour la base de données, c’est facile : hormis SQLite qui est hors-jeu en raison de ses faibles performances, tous les SGBD modernes comme PostgreSQL sont conçus pour fonctionner en réseau. Il suffit d’exposer l’IP et le port du serveur PostgreSQL distant auprès de la machine concernée et le tour est joué.
Afin de répliquer la base de données sur plusieurs machines et éventuellement répartir la charge, il existe des solutions comme pgpool ou pgBouncer.
Pour le cache : nous avons bien souvent affaire à Redis, un cache performant qui fonctionne également en réseau. Cela dit, en raison de la nature même du service (un cache est censé être rapide et les données hébergées dessus sont a priori éphémères ou non critiques), il est sans doute plus raisonnable de l’héberger sur le serveur de calcul malgré tout. Nous l’exposerons alors dans un réseau virtuel pour le mutualiser entre plusieurs instances d’un service en cas de besoin.
La réplication des données de Redis en temps réel peut être réalisée avec les fonctionnalités intégrées Sentinel et Cluster.
🔗Les données des utilisateur·ices
Par défaut, la plupart des logiciels conservent les données sur le système de fichiers de l’hôte (ext4, btrfs, zfs…), dans un volume Docker pour notre cas.
C’est là où cela devient compliqué (coûteux ou difficile) si nous souhaitons stocker ces données sur un serveur de stockage distant.
Il existe des protocoles et des outils pour servir des fichiers sur un réseau comme NFS, GlusterFS, Ceph, ZFS, ou même iSCSI ou SSHFS, mais ils portent tous leur lot de contraintes et de défauts :
- NFS est peu coûteux mais n’est pas aussi performant que d’autres et ne gère pas l’ownership des fichiers, causant des problèmes de compatibilité avec de nombreux logiciels ;
- ZFS, GlusterFS et Ceph peuvent rapidement consommer plusieurs Go de RAM et pas mal de CPU pour assurer la duplication des données ;
- iSCSI est trop « bas niveau » pour être utile ou performant et SSHFS n’est pas performant du tout.
Après avoir expérimenté NFS pendant plusieurs années, nous avons fini par tester le protocole S3 pour créer des espaces de stockage objet : nous utilisons l’outil Garage, maintenu par l’association DeuxFleurs comme alternative à Minio (également open-source, mais Garage c’est mieux).
Le stockage objet suit une approche complètement différente pour conserver les données : il n’existe pas de hiérarchie de fichiers, et chaque fichier se voit attribuer un identifiant unique comme nom de fichier. Ces fichiers (alors nommés objets) sont conservés dans des « buckets » (des seaux, littéralement) qui constituent l’espace de stockage attribué, et sont accessibles à l’aide d’une clé composée d’un identifiant et d’un secret.
Dans certains logiciels, S3 peut être choisi comme backend de stockage pour les données des utilisateur·ices. Avec ce mode de stockage, le bucket S3 distant est servi par HTTP. De son côté, Garage peut être configuré pour dupliquer le bucket en temps réel sur plusieurs machines.
Malheureusement, S3 n’est pas supporté par tous les logiciels. Dans de nombreux cas, il sera nécessaire de stocker les fichiers sur le serveur qui héberge le service et de trouver d’autres méthodes pour la réplication si nécessaire.
Nous allons maintenant voir comment nous pouvons utiliser l’ensemble de ces outils pour créer des fabriques à services.
🔗La fabrique à Nextcloud
Nextcloud, la suite logicielle pensée pour le travail en collaboration dans une équipe qui se présente comme une alternative à la Google Suite, est une application PHP assez lourde qui peut s’avérer complexe à maintenir. Elle dépend de plein de petits services annexes : un cache Redis, une base de données PostgreSQL, un serveur Collabora Office, un sidecar Cron, un reverse-proxy…
Initialement, nous partions d’une installation unique de Nextcloud, mutualisée entre tous nos membres.
Mais en souhaitant fournir des services pour des organisations, nous avons réalisé qu’il ne serait pas possible de fournir un niveau de service décent en n’utilisant qu’une seule instance Nextcloud partagée entre toutes les organisations (même en utilisant les groupes) : les utilisateur·ices ne sont pas cloisonné·es par organisation, la configuration est la même pour tout le monde, certaines données sont partagées…
Par ailleurs, le logiciel de Nextcloud n’est pas conçu pour être multitenant : on ne peut pas facilement utiliser une seule et même instance de Nextcloud pour faire tourner plusieurs environnements différents avec des données et une configuration différentes. Il nous faut donc faire un peu de bidouillage pour rendre une instance duplicable facilement.
Et ça tombe bien : il existe un exemple récent de fabrique à Nextcloud qui fonctionne bien, avec plus de 1 500 organisations bénéficiaires : Frama.space, maintenu par Framasoft, qui utilise toute une panoplie de scripts et de logiciels pour automatiser le déploiement d’une nouvelle instance très rapidement : Charon pour l’inscription, Chronos pour les tâches récurrentes, un patch de Collabora, Asclépios pour patcher Nextcloud, Argos pour la supervision, Déméter, Hermès, Poséidon et toute la fratrie.
Une vidéo de présentation du fonctionnement interne de Framaspace est disponible sur PeerTube, et nous a beaucoup aidé pour penser le fonctionnement de cette fabrique. Cela dit, nous n’avons pas pu directement réutiliser le travail de Framasoft, car la plupart des composants de cette stack technique sont intrinsèquement liés à leur infrastructure.
Nous allons donc devoir bidouiller Nextcloud à notre sauce. Pour comprendre notre démarche, partons d’une installation multi-instances standard : imaginons que vous hébergez trois instances.
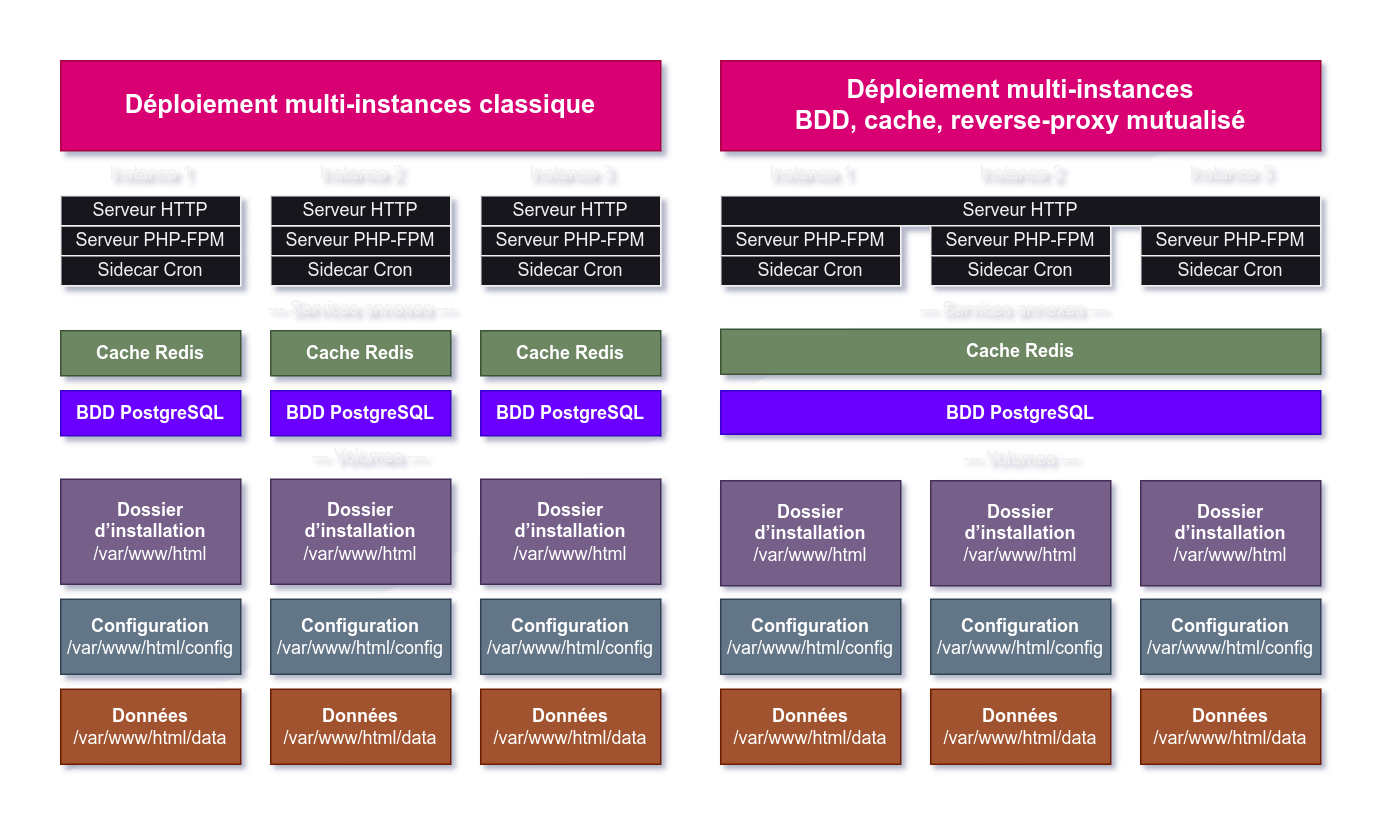
L’installation de gauche est assez typique d’un déploiement de plusieurs instances dans des machines virtuelles.
Pour trois instances Nextcloud, on y compte trois services propres à l’instance : le serveur HTTP, le serveur PHP-FPM et le sidecar Cron. Parfois, les trois services sont fusionnés en un seul, notamment si l’on utilise l’image Nextcloud apache et la webcron… mais cela impacte fortement les performances de Nextcloud.
Avec ça, nous avons aussi deux services annexes qui ne sont pas propres à Nextcloud mais dont Nextcloud est dépendant : la base de données PostgreSQL et le cache Redis (ce dernier est facultatif mais améliore grandement les performances).
Ensuite, chaque instance va disposer de trois volumes :
- le dossier d’installation, monté sur
/var/www/html/, qui contient les fichiers système de Nextcloud et pèse environ 1 Go ; - le dossier réservé à la configuration, monté sur
/var/www/html/config/, très léger ; - le dossier des données sur
/var/www/html/data/.
Et enfin, ils ne sont pas notés ici, mais d’autres services annexes peuvent être nécessaires :
- le serveur Collabora Office (ou Onlyoffice) pour éditer des documents Office en collaboration ;
- le serveur TURN/STUN pour utiliser Nextcloud Talk ;
- un serveur Imaginary pour générer des miniatures ;
- d’autres éventuels services tiers.
Comme vous pouvez le constater, ça nous amène à maintenir un nombre très conséquent de services par instance.
Pour notre part, nous partons plutôt de l’installation de droite, qui reste assez courante, en mutualisant certaines ressources :
- la base de données et le cache sont partagés ;
- notre reverse-proxy Caddy est partagé entre tous nos services et sert directement les fichiers de l’instance Nextcloud.
Mais ce niveau de mutualisation n’est pas encore suffisant à notre goût à partir du moment où l’on souhaite héberger plusieurs instances Nextcloud.
🔗Les données
Cette partie-là devient très simple grâce à S3 : nous pouvons créer un bucket par instance et stocker les données dessus. Le volume de données disparaît et se fait remplacer par un service annexe, Garage, accessible en réseau.
🔗Le dossier d’installation
Le dossier d’installation, c’est le volume dans lequel Nextcloud conserve ses fichiers système : ses composants, ses plugins… tout le « cœur » de Nextcloud est conservé dedans. Les fichiers stockés à l’intérieur ne bougent pas sauf en cas de mise à jour de Nextcloud ou ses plugins.
Donc, pour trois instances Nextcloud de même version et avec les mêmes plugins, le dossier d’installation sera identique. C’est intéressant, car ça signifie qu’il y a moyen de mutualiser cette ressource entre les instances. Il y a d’autant plus un gros intérêt à mutualiser ce dossier puisqu’il pèse 1.2 Go par instance (rien que ça…).
Malheureusement, Nextcloud n’aime pas du tout l’idée : à chaque démarrage, il effectue quelques opérations dérangeantes :
- il utilise un fichier pour verrouiller le dossier en écriture et refusera de démarrer si ce fichier de verrou est présent, signifiant qu’une autre instance l’utilise ;
- il tente de mettre à jour les fichiers de ce dossier s’il détecte qu’une mise à jour est disponible… mais cela impactera nécessairement les autres instances.
Nous avons donc patché le script de démarrage de Nextcloud pour désactiver toutes les interactions de Nextcloud avec ce dossier.
Nous arrivons ainsi à la configuration suivante :
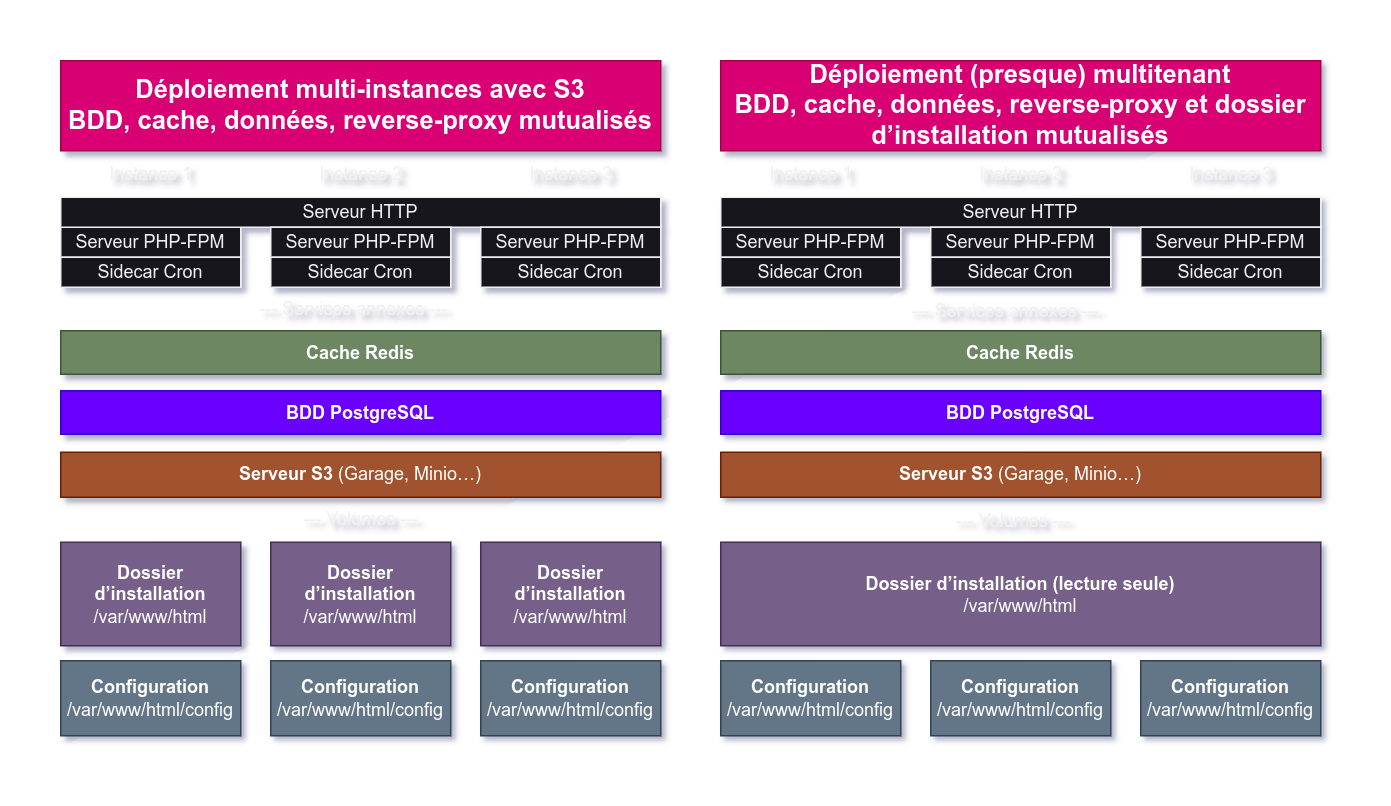
À gauche : une installation sans mutualiser le dossier d’installation. À droite, notre configuration finale.
Nous avons encore quelques pistes d’amélioration possibles :
- pour éviter que toutes les cron de nos instances Nextcloud se produisent au même moment et surchargent le serveur, nous pourrions voir dans quelle mesure nous pouvons réutiliser Chronos, utilisé par Framaspace pour créer une « queue de crons », à cet usage ;
- nous pourrions théoriquement utiliser une seule instance de PHP-FPM en changeant le dossier de configuration en fonction du nom d’hôte comme le fait Framaspace (tel que présenté dans leur vidéo), et ainsi parvenir à une installation réellement multitenant ;
- nous aurions besoin d’une instance de Imaginary pour décharger le serveur PHP de la génération des miniatures ;
- il nous faudra sans doute installer une instance de Collabora patchée à partir d’un certain stade.
Notez par ailleurs que notre dossier d’installation est monté sur toutes nos instances en lecture seule.
🔗La configuration
Enfin, il ne reste plus que le volume de configuration qui contient moins de 5 Ko de fichiers… que nous n’avons pas encore réussi à délocaliser. Mais comme il s’agit d’un tout petit volume, ce n’est pas très grave.
Par contre, il nous faut y ajouter quelques paramètres pour que notre bidouillage du dossier d’installation ne pose pas de problème :
'updatechecker' => false,pour désactiver la vérification des nouvelles mises à jour (on s’en occupe nous-mêmes) ;'appstoreenabled' => false,pour désactiver l’installation et la mise à jour d’applications via le store de Nextcloud.
Pour le reste de la configuration, nous utiliserons les variables d’environnement pour provisionner une nouvelle installation avec la configuration souhaitée :
POSTGRES_*pour configurer une nouvelle base de données ;SMTP_*etMAIL_*pour configurer l’envoi d’e-mails ;OBJECTSTORE_S3_*pour le stockage des données ;NEXTCLOUD_TRUSTED_DOMAINSetTRUSTED_PROXIESpour configurer le reverse-proxy et le nom d’hôte ;REDIS_HOST_*pour le cache Redis ;NEXTCLOUD_ADMIN_*pour créer un compte d’administration ;NEXTCLOUD_UPDATE=0pour désactiver la mise à jour de Nextcloud au démarrage ;NEXTCLOUD_DATA_DIR=/datacomme volume de données fictif dans lequel nous ajoutons un fichier.ocdata. Les données étant stockées dans le bucket S3, le dossier de données ne nous est pas utile.
🔗Les plugins
Nous ajoutons et configurons deux applications supplémentaires à Nextcloud :
- l’application de Collabora Office pour l’édition de documents en collaboration ;
- l’app OpenID Connect pour connecter Nextcloud à notre fournisseur d’authentification.
🔗La maintenance
Maintenant que nous avons une installation complète, voyons comment nous pouvons simplement ajouter une nouvelle instance et mettre à jour des applications.
Pour déployer une nouvelle instance : on utilise un conteneur Nextcloud éphémère pour initialiser le dossier de configuration, le bucket S3 et la base de données ; il utilise l’image officielle (et pas notre image patchée), il va donc effectuer tout le processus d’initialisation et de mise à jour. Une fois initialisé, nous arrêtons le conteneur et nous ajoutons la nouvelle instance à notre grappe de Nextcloud avec les autres instances que nous hébergeons, sur notre dépôt Core.
Pour réaliser une mise à jour de Nextcloud ou des applications : nous passons toutes les instances en mode maintenance, puis nous utilisons un conteneur éphémère qui utilise l’image officielle pour mettre à jour le dossier d’installation de Nextcloud, qui est monté en lecture et écriture sur ce conteneur. Cette procédure met à jour toutes les instances simultanément. Une fois la mise à jour terminée, nous utilisons la commande ./occ upgrade sur chaque instance pour mettre à jour chacune des bases de données, puis nous désactivons le mode maintenance.
🔗La fabrique à Paheko
Pour Paheko, logiciel de comptabilité libre et de gestion d’adhérent·es, le processus est un peu plus facile mais nous a nécessité beaucoup de préparation. Le logiciel supporte nativement les installations multitenant, mais nous a nécessité pas mal de bidouillage : Paheko fournit un fichier de configuration spécifique pour ce genre d’installation, et les scripts habituels (pour les crons, emails) sont différents d’une installation habituelle.
En bref : c’est supporté, mais il faut greffer soi-même les modules nécessaires et sans doute toucher un peu au code PHP.
Nous avons créé une image Docker pour Paheko qui comporte plusieurs avantages par rapport à une installation classique :
- l’instance est conçue pour être multi-site, pas besoin de bidouiller ;
- les noms de domaine sont entièrement personnalisables : avec le fichier de configuration fourni, il était uniquement possible de créer des sous-domaines (ex.: monasso.paheko.cloud…).
- on utilise une image alpine PHP-FPM plutôt qu’un serveur Apache, ce qui nous permet de servir Paheko avec notre reverse-proxy Caddy en HTTP/3 sans passer par un serveur HTTP intermédiaire et offre un gain de performance ;
- intégration native des crons système ;
- le conteneur n’est pas privilégié, rien ne tourne en root (pas même les cron ni le serveur PHP-FPM) ;
- notre image supporte l’envoi d’e-mails en masse et la gestion des bounces (emails retournés à l’expéditeur·ice) ;
- la configuration peut être provisionnée avec des variables d’environnement.

🔗La configuration SSO
Paheko permet une utilisation du logiciel avec un SSO, mais on ne peut pas dire pour autant que le logiciel supporte cet usage à proprement parler. Une page de wiki y est consacrée.
Pour faire simple : il faut écrire soi-même l’intégration du SSO en PHP. Ce n’est pas évident ni accessible et nous n’avions qu’assez peu de temps à y consacrer, nous avons donc opté pour un autre choix : utiliser un compte admin générique. Toutes les personnes qui ont reçu l’accès à l’instance de comptabilité de leur organisation est donc admin.
Il n’y a donc pas d’historique nominatif des actions, ce qui reste quand même assez problématique à notre goût pour la comptabilité, mais on vit avec ce compromis.
La vraie gestion du SSO passe en réalité par le plugin caddy-security que nous utilisons comme mur d’authentification OIDC, et qui vérifie si l’utilisateur·ice dispose des bons rôles pour accéder à la comptabilité. Finalement, nous n’utilisons pas du tout Paheko pour gérer OIDC.
🔗Les lacunes de Paheko
Paheko a l’avantage d’être très léger et efficient en termes de consommation de ressources (absolument rien à voir avec Nextcloud). Une seule instance du logiciel peut héberger plusieurs organisations sans broncher.
Il présente toutefois plusieurs inconvénients notables :
Paheko supporte uniquement SQLite. Cela ne pose pas de problème de performance mais rend difficilement envisageable une installation hautement disponible / répartie sur plusieurs serveurs. Le volume contenant les données utilisateur·ices peut rapidement peser plusieurs Go, et le synchroniser en temps réel d’un serveur à un autre peut s’avérer compliqué comme nous l’écrivions plus haut.
Paheko ne supporte pas le protocole S3. Les fichiers (et notamment les pièces jointes aux écritures comptables) sont soit intégrées à la base de données SQLite (ce qui ne va pas améliorer son poids…), soit gérée sur le système de fichiers de l’hôte. Cela nous amène aux mêmes contraintes qu’énoncées ci-dessus : difficile d’imaginer un serveur hautement disponible dans cette configuration-là.
Les sources d’authentification tierces ne sont pas bien intégrées. Comme nous l’écrivions ci-dessus, intégrer un SSO relève plutôt de la bidouille que d’une intégration logicielle à proprement parler et nous a mené à faire des compromis.
Ces faiblesses se compensent avec une gestion assez simplifiée du stockage des données et de la maintenance : certes, Paheko dépend d’une gestion assez « old-school » (monolithique) de l’espace de stockage et des données, mais tout repose dans un seul volume. Même si l’on doit héberger 50 organisations, il n’y aura toujours qu’un seul volume à sauvegarder / redonder. On est très loin de la prise de tête que représente l’hébergement d’une grappe de Nextcloud.
Mettre à jour toutes les instances Paheko reste extrêmement simple : de notre côté, il nous suffit juste de changer le numéro de version et de régénérer notre image Docker, et les instances se mettront à jour tour à tour lors de la prochaine visite de ses utilisateur·ices. Prenez gare toutefois aux mises à jour qui cassent l’installation ; heureusement, le changelog est bien renseigné.
Pour créer une nouvelle instance, rien de plus simple : il suffit de créer un dossier au nom de domaine de la nouvelle instance dans le volume de Paheko, dossier users/. Cela s’ensuit pour notre part par une configuration du module caddy-security pour la gestion du SSO.
🔗La fabrique à WordPress
WordPress, c’est le logiciel le plus utilisé au monde pour concevoir des sites web (rien que ça), et c’est libre (yay).
De par sa maturité, WordPress intègre depuis longtemps la fonctionnalité Multisite pour mettre en place une instance multitenant.
WordPress étant très répandu, ce logiciel est particulièrement dangereux à héberger car une faille de sécurité trouvée est vite exploitée. Avoir une instance Multisite simplifie énormément la maintenance : au lieu de devoir mettre à jour individuellement chaque instance, nous pouvons simplement nous contenter de maintenir à jour l’unique instance Multisite.
Un autre grand avantage de cette configuration : la fonctionnalité Multisite est vraiment pensée pour nous simplifier le déploiement d’un nouveau site en un clic. C’est même encore plus simple qu’avec Paheko puisque cela peut se faire via l’interface web.
Cet environnement vient toutefois avec son lot d’inconvénients.
🔗Les inconvénients d’une installation Multisite
Verrouillage des thèmes et plugins. Pour nos utilisateur·ices, il n’est pas possible d’installer de nouveaux thèmes ou des plugins personnalisés. Étant donné que la plupart des failles de sécurité de WordPress proviennent des plugins, il faut plutôt voir ça comme un atout… mais ça reste contraignant. Pour les thèmes, nous avons préinstallé une trentaine de thèmes populaires, et si les organisations qu’on héberge souhaitent un thème en particulier, elles peuvent nous demander de l’installer.
Une seule faille compromet tous les sites. Si une faille de sécurité est découverte dans l’un des sites hébergés, il est assez probable que les autres sites soient également compromis.
Les hausses de trafic : si l’un des sites hébergés est fortement fréquenté d’un coup, les autres sites seront ralentis également.
Tout repose sur une instance. Si l’instance Multisite tombe, tous les sites tombent avec elle.
Nous allons maintenant vous présenter les parades que nous avons trouvées pour éviter ces inconvénients.
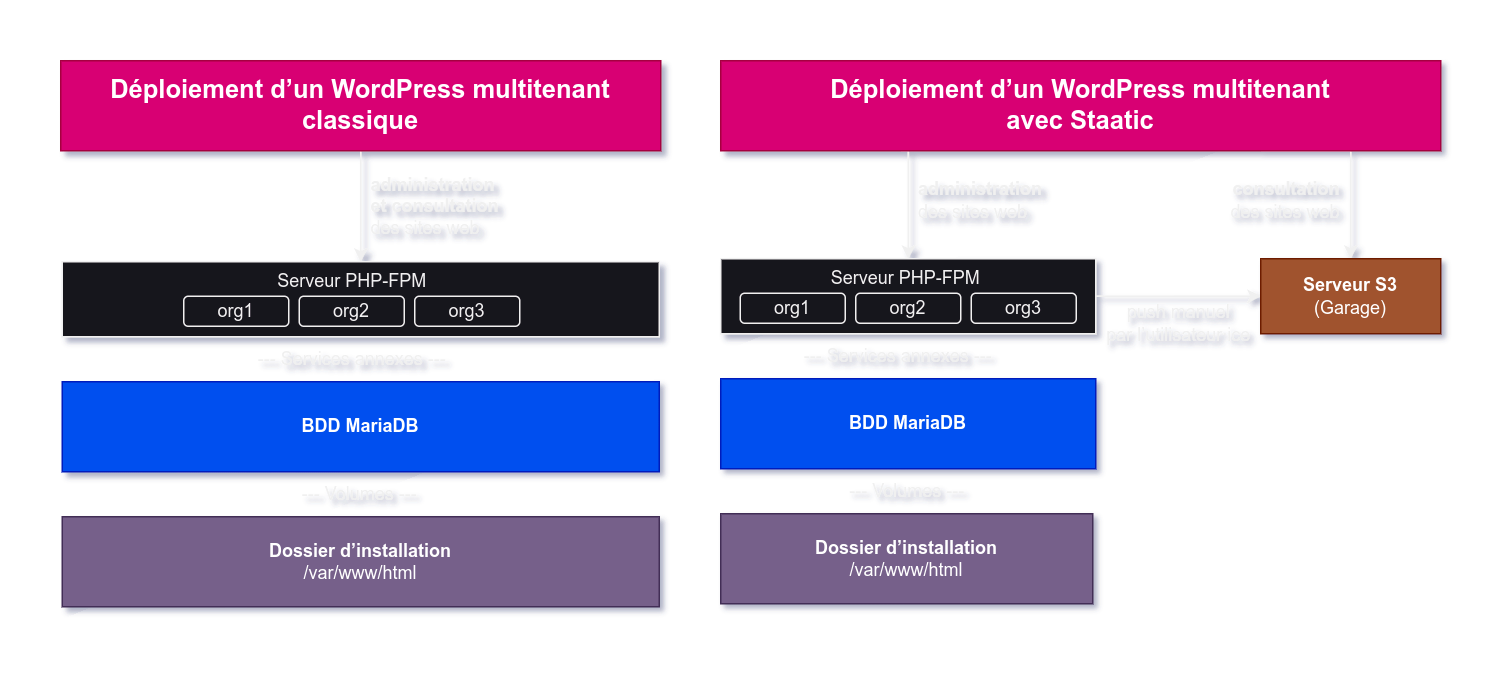
🔗Staatic pour contrer les inconvénients
Staatic, c’est un plugin WordPress qui permet de créer un site statique à partir d’un site WordPress. Il fonctionne en indexant le site web puis en l’envoyant sur le support de stockage souhaité (S3, dossier local, FTP, GitHub Pages…). Nous avons naturellement choisi S3 comme support de destination.
La publication d’un site est déclenchée manuellement, en appuyant sur un bouton « Publier » dans l’interface d’administration d’un site web ; le site WordPress en lui-même devient alors un espace de pré-production pour nos utilisateur·ices avant d’envoyer le site sur le bucket S3.
Garage, notre serveur S3, est configurable pour servir le contenu d’un bucket S3 via HTTP sans authentification, comme c’est déjà le cas pour servir ce présent site web ou notre documentation ; en parallèle, il duplique en temps réel les sites web qu’il héberge sur trois serveurs différents, permettant de répartir la charge du trafic si besoin.
Ainsi, en cas de panne de l’instance WordPress multisite, l’espace d’administration des sites sera indisponible, mais rien d’autre ne bougera : les sites resteront en ligne puisqu’ils sont hébergés sur Garage.
Par ailleurs, les sites statiques sont par essence beaucoup plus rapides que les sites WordPress classiques. Les pages HTML sont servies directement, sans être traitées par un serveur PHP.
Et enfin, en termes de sécurité : plus rien ne nous oblige à exposer l’instance WordPress en elle-même puisqu’elle est simplement utilisée pour concevoir le site, elle ne le sert pas directement aux personnes qui vont le consulter. Nous pouvons donc mettre un mur d’authentification sur toute l’instance WordPress.
Le seul inconvénient majeur de cette configuration, c’est l’impossibilité d’héberger du contenu dynamique sur le site. Pas de formulaire de contact, de plugin de réservation, ou d’autres usages potentiellement intéressants : c’est bien pour un site vitrine ou un blog, mais on atteint vite ses limites. Mais ça nous simplifie aussi énormément la maintenance et ça diminue drastiquement la surface d’attaque : c’est le meilleur compromis que nous ayons trouvé.
Bien évidemment, dans notre offre d’hébergement de site web, nous proposerons aussi d’héberger un bucket S3 brut, sans WordPress, pour servir un site statique pour les geeks qui savent faire ; mais cela ne concerne pas la majorité du public que nous souhaitons atteindre.
🔗Les autres logiciels de notre stack
Nous avons fait le tour des trois logiciels pour lesquels nous avons les résultats les plus aboutis après plusieurs mois de travail, mais nous avons aussi amélioré d’autres aspects de notre infrastructure logicielle que nous souhaiterions vous présenter.
🔗Listmonk
Nous avons la chance de pouvoir bénéficier immédiatement de la nouvelle version de Listmonk qui supporte désormais une utilisation multi-utilisateur·ices et intègre OpenID Connect. Le logiciel sert à envoyer des newsletters, ce que Paheko permet déjà, mais les usages varient.
Listmonk supporte également un backend S3 pour l’hébergement de fichiers joints aux emails.
🔗MX secondaire et newsletters
En bidouillant une nouvelle instance de docker-mailserver, que nous utilisons depuis 6 ans pour héberger nos e-mails, nous avons mis en place un serveur mail secondaire qui peut recevoir des emails si l’instance principale tombe en panne.
Cette instance est hébergée sur un serveur dédié à cet usage (stanley).
C’est ce serveur secondaire qui est utilisé par Paheko et Listmonk pour envoyer des mails en masse, plutôt que notre serveur principal : en effet, l’envoi de mails en masse provoque immédiatement un ralentissement de la distribution des e-mails en raison de rate limits imposés par les géants (en particulier par Google).
Ainsi, pour nous éviter que les boîtes e-mail de tous nos membres se retrouvent temporairement bloqués (pendant plusieurs heures !) par Google, nous utilisons ce serveur secondaire qui subira le rate limit à la place de notre serveur principal.
Pour cette même raison, un peu plus tôt dans l’année, nous avons été contraint·es de limiter l’usage de notre service mail pour empêcher que des associations puissent l’utiliser pour envoyer des emails à plusieurs dizaines de personnes en même temps (ce qui a entraîné des retards de distribution) en incitant plutôt à utiliser un service de newsletter pour cet usage, qu’il s’agisse du nôtre ou ailleurs, et ce dans l’unique but d’assurer la bonne distribution des correspondances de nos membres.
🔗Gestion de noms de domaine
Pour simplifier le travail de certaines structures que nous accompagnons, nous intervenons parfois directement sur les noms de domaine de leurs organisations qui nous en ont donné leur accord.
Pour l’instant, nous utilisons le logiciel HappyDomain pour gérer leurs zones DNS. HappyDomain fonctionne en récupérant des droits sur l’API des bureaux d’enregistrement et supporte de nombreux fournisseurs… Mais ce logiciel est assez peu abouti, contient des bugs et semble peu maintenu, ce qui nous encourage à rechercher des alternatives.
🔗Supervision interne
Nous avons retravaillé notre supervision interne cette année : nous avons quitté Netdata qui change sa licence et incorpore désormais des morceaux de code propriétaires, pour migrer vers une stack Telegraf + InfluxDB + Grafana. Cette stack fonctionne à merveille pour l’instant.
Alex, membre de notre Comité de Contribution, a tenu une conférence à ce sujet au Capitole du Libre 2024.
🔗Service mail
Nous avons considérablement amélioré notre service mail cette année, d’une part à l’aide de l’intégration de notre MX secondaire mentionné plus haut, et d’autre part grâce à l’ajout d’une nouvelle webmail qui fonctionne à l’aide de Roundcube.
Nous réservons encore à nos membres un beau cadeau pour l’année prochaine : Hannaeko et Neil travaillent sur une nouvelle brique logicielle qui va remplacer l’interface que nous utilisons aujourd’hui pour ajouter des alias et des boîtes mail par un nouveau logiciel remis au goût du jour, qui utilisera OpenID Connect pour authentifier les membres.
Nous espérons par ailleurs que ce projet pourra servir aux développeur·euses et utilisateur·ices de docker-mailserver comme API et frontend pour utiliser le service.
🔗CI/CD et images Docker
Enfin, dans les dernières grandes nouveautés de l’année, nous utilisons l’un de nos nouveaux serveurs au Bêta (monacha) pour exécuter des CI/CD sur nos dépôts à l’aide du runner act modifié par Gitea.
Ce nouvel outil nous permet de déployer automatiquement ce site web, notre documentation, et recompile également nos binaires dont (rs-short, autodiscover ou constello) à chaque nouveau commit sur la branche principale. Il génère une image Docker pour chacun de ces logiciels, qui sont hébergées sur notre forge.
Cela nous simplifie considérablement le déploiement d’une mise à jour : fini le temps où nous compilions les binaires de production sur nos ordinateurs ! Nous avons maintenant un serveur pour ça.
🔗Qu’allons-nous faire ensuite ?
Pour conclure cette série de trois articles bien longs (plus d’une heure de lecture au total ?!) sur les améliorations techniques à La Contre-Voie, voilà notre plan pour l’année à venir.
🔗S’étendre
Tout d’abord, nous allons poursuivre l’expansion de notre offre de services comme nous l’avons annoncé précédemment : nous allons mettre à contribution tous ces nouveaux serveurs pour héberger nos nouveaux outils, en commençant par les services à la carte (dont PeerTube qui n’est pas encore en place), puis en ajoutant les services sur inscription (gratuite) que nous aimerions vous mettre à disposition.
À ce moment-là, nous effectuerons (enfin !) la migration de notre ancien service membre vers notre nouveau SSO après avoir achevé les différents prérequis techniques pour cette migration (développement d’un captcha, gestion des adhésions dans Keycloak, déploiement de la nouvelle interface du service mail et intégration de nos services historiques Git et Nextcloud).
Sur cette base, nous construirons une offre de services gratuite à l’usage (financée par vos dons et nos autres actions), unifiée, qui ne nécessitera que la création d’un compte sur notre SSO.
🔗Consolider
Ensuite, nous travaillerons sur les finitions de cette offre de service en ajoutant les rouages qui manquent. En vrac : écrire un outil de gestion d’adhésions pour nous, développer un outil de gestion de droits pour que nos organisations bénéficiaires puissent administrer leurs équipes, écrire des configurations pour améliorer la supervision de nos services, contribuer à des outils que nous utilisons…
Nous prendrons également un temps pour faire le point sur notre précédente offre de services, en place depuis 2019 : que faire de sncf, l’outil derrière notre service Forms, que nous n’avons plus le temps de maintenir ? Quelle direction prendre pour notre service Draw qui est vraiment très peu utilisé, ou bien notre service Liens qui héberge régulièrement des liens de hameçonnage et nous coûte du temps de modération ? Nous prendrons le temps de jeter un coup d’œil dans le rétroviseur et d’adapter notre trajectoire en conséquence.
Enfin, cette consolidation se fera aussi dans les coulisses : nous reverrons la répartition de ces services sur nos différents serveurs pour créer une redondance de données en temps réel, se prémunir plus efficacement des risques d’une défaillance d’un disque dur, automatiser des processus de mise à jour et d’entretien, prendre le temps de faire les choses bien quitte à ralentir un peu.
Le travail de consolidation est assez peu gratifiant (on ne lance pas un nouveau service, c’est de la maintenance) et plutôt invisible (on n’annoncera pas qu’on maintient un service, c’est ce qui est attendu de nous, c’est considéré comme un dû), et pourtant, il s’agit d’une étape absolument incontournable.
🔗Documenter
En parallèle avec ce travail de consolidation, nous continuerons à documenter et expliciter nos démarches, sur notre documentation autant que sur ce présent blog (bien que nos publications soient bien irrégulières…), pour toujours essaimer nos connaissances autant que possible, durant tout le long de cette transformation de nos services.
L’année dernière, nous avions déjà consacré beaucoup de temps à notre plateforme de documentation, et nous continuerons à l’enrichir au fil du temps.
🔗… si nous parvenons à exister
Nous ne sommes qu’une petite dizaine, avec une personne bénévole à temps plein depuis 6 ans − et qui ne peut rester seulement bénévole bien longtemps encore.
Il y a trois ans, nous partions encore d’un budget annuel de 2 000 € et pourtant, nous persistons encore aujourd’hui à l’idée que nous pouvons passer à la vitesse supérieure et commencer à salarier, pour aider à faire évoluer les pratiques numériques d’un maximum de personnes.
Nous ne savons pas encore si nous aurons les moyens financiers d’atteindre les 12 000 € d’objectif de notre campagne de dons qui, si complétée par des cotisations, des subventions, des interventions éducatives rémunérées, de l’hébergement de services et d’autres sources encore, nous donneront peut-être les capacités de payer un SMIC à temps plein.
Souhaitez-vous nous soutenir pour y parvenir ?
Si vous avez apprécié lire ces articles, que vous pensez que ça vaut la peine de tenter le coup, que vous aimeriez nous lire encore, alors vous pouvez nous faire un don :
C’est grâce à vous que nous en sommes là. Merci pour votre soutien, et à la semaine prochaine pour un nouvel article, moins technique cette fois-ci !