
Golden ticket to visit our service factories
Technique, part 3: The inner workings of our duplicable tools
This is the last article in the series dedicated to La Contre-Voie’s technical infrastructure! Next week, we’ll resume our usual editorial line :)
After having presented the hardware used for our computer servers, then the unified authentication module that connects our services together, it’s about time to introduce the software that runs our new services!
You will find here the technical documentation we use to maintain our historical services.
Meanwhile, our new “à la carte” services are not yet documented as they are not yet officially released: they are used for our experimental digital support program and we hope to officially inaugurate them by mid-2025.
In the meantime, in this article, we give you the golden ticket to visit our service factories! Those who follow us will see that our methods have significantly evolved compared to our previous infrastructure.
🔗What’s a service factory?
Sometimes referred to as a service farm or a multi-site deployment, we define it as a set of processes that enable us to effortlessly duplicate a service, hosting it for as many people or organizations as required, while minimizing the cost and time spent on deploying a new clone.
Each of these copies of the service separes data and configuration between each organization, but shares other resources: databases, caches, HTTP server, system folders… the aim being to pool as many resources as possible.
Sometimes we even pool the software instance while maintaining data separation, in which case we call it a multi-tenant configuration! But this is not always possible with the software we host.
To take the example of WordPress: if we need to host 20 organizations, that would initially require us to host 20 different instances of WordPress, which implies keeping them all up to date, configuring them individually, monitoring them… and having sufficient resources (memory, CPU) to host them.
Later in this article, we’ll look at how we can technically host 20 organizations with a single instance of WordPress, without compromising on performance or stability, and without running the risk of all 20 websites being unavailable if the single instance goes down!
We’ll also present the double challenge of having reproducible instances, but also of integrating OpenID Connect authentication to connect each of these services to our SSO.
🔗Data management
But first, we need to establish how we’re going to store user data. This is the first fundamental building block in creating a service factory: if this part is well thought-out, the service will be easily reproducible later on.
Currently, we have eight servers in production. These servers may share the service hosting load between them. We may also need to quickly switch an instance of a service to another server.
More commonly still, we might want to separate storage and computation on different machines: one group of machines with lots of storage space whose role is to keep data files and serve as a database, and another group that hosts software instances and various programs that manipulate this data.
The challenge is therefore to make the hosted data accessible over the network from another server, and to avoid storing data locally as much as possible.
🔗Database and cache
For the database, it’s easy: with the exception of SQLite, which is out of the game due to its poor performance, all modern DBMS such as PostgreSQL are designed to work over a network. All you need to do is expose the IP and port of the remote PostgreSQL server to the machine concerned, and you’re ready to go.
Solutions such as pgpool or pgBouncer can be used to replicate the database on several machines and distribute the load.
For caching: we often have to deal with Redis, a high-performance cache that also works over a network. That said, given the very nature of the service (a cache is supposed to be fast and the data hosted on it is likely ephemeral or non-critical), it’s probably more reasonable to host it on the compute server. We’ll then expose it in a virtual network, so that it can be shared between several instances of a service if need be.
Real-time replication of Redis data can be achieved using the built-in Sentinel and Cluster features.
🔗User data
By default, most software stores data on the host file system (ext4, btrfs, zfs…), in a Docker volume in our case.
This is where it gets complicated (expensive or difficult) if we want to store this data on a remote storage server.
There are protocols and tools for serving files over a network such as NFS, GlusterFS, Ceph, ZFS, or even iSCSI or SSHFS, but they all carry their share of constraints and shortcomings:
- NFS is inexpensive, but doesn’t perform as well as others, and doesn’t handle ownership of files, causing compatibility problems with many software packages;
- ZFS, GlusterFS and Ceph can quickly consume several GB of RAM and quite a lot of CPU to ensure data duplication;
- iSCSI is too “low-level” to be useful or efficient and SSHFS is not efficient at all.
After experimenting with NFS for several years, we ended up testing the S3 protocol to create object storage spaces: we use Garage, maintained by DeuxFleurs as an alternative to Minio (also open-source, but Garage is better).
Object storage takes a completely different approach to data storage: there is no file hierarchy, and each file is assigned a unique identifier as its filename. These files (then called objects) are kept in “buckets” which constitute the allocated storage space, and are accessed using a key made up of an identifier and a secret.
In some software applications, S3 can be chosen as the storage backend for user data. With this storage mode, the remote S3 bucket is served via HTTP. For its part, Garage can be configured to duplicate the bucket in real time across multiple machines.
Unfortunately, not all software supports S3. In many cases, it will be necessary to store files on the server hosting the service and find other methods for replication if necessary.
We’ll now look at how we can use all these tools to create service factories.
🔗The Nextcloud factory
Nextcloud, the software suite designed for collaborative teamwork that presents itself as an alternative to Google Suite, is a fairly heavy PHP application that can be complex to maintain. It is dependent on a number of small auxiliary services: a Redis cache, a PostgreSQL database, a Collabora Office server, a Cron sidecar, a reverse-proxy…
Initially, we started with a single installation of Nextcloud, shared between all our members.
But when we wanted to provide services for organizations, we realized that it would not be possible to provide a decent level of service using a single Nextcloud instance shared between all organizations (even using groups): users are not partitioned by organization, configuration is the same for everyone, some data is shared…
Furthermore, Nextcloud’s software is not designed to be multi-tenant: we can’t easily use a single instance of Nextcloud to run several different environments with different data and configuration. So we need to do a bit of tinkering to make an instance easily duplicable.
And just in time: there’s a recent example of a successful Nextcloud factory, with over 1,500 beneficiary organizations: Frama.space, maintained by Framasoft, which uses a whole panoply of scripts and software to automate the deployment of a new instance very quickly: Charon for registration, Chronos for recurring tasks, a Collabora patch, Asclepios to patch Nextcloud, Argos for supervision, Demeter, Hermes, Poseidon and all the siblings.
A video presentation of the internal workings of Framaspace is available on PeerTube, and helped us a lot in thinking about how this factory works. That said, we couldn’t directly reuse Framasoft’s work, as most of the components of this technical stack are intrinsically linked to their infrastructure.
So we’re going to have to tinker with Nextcloud in our own way. To understand our approach, let’s start with a standard multi-instance installation: Let’s imagine you’re hosting three instances.
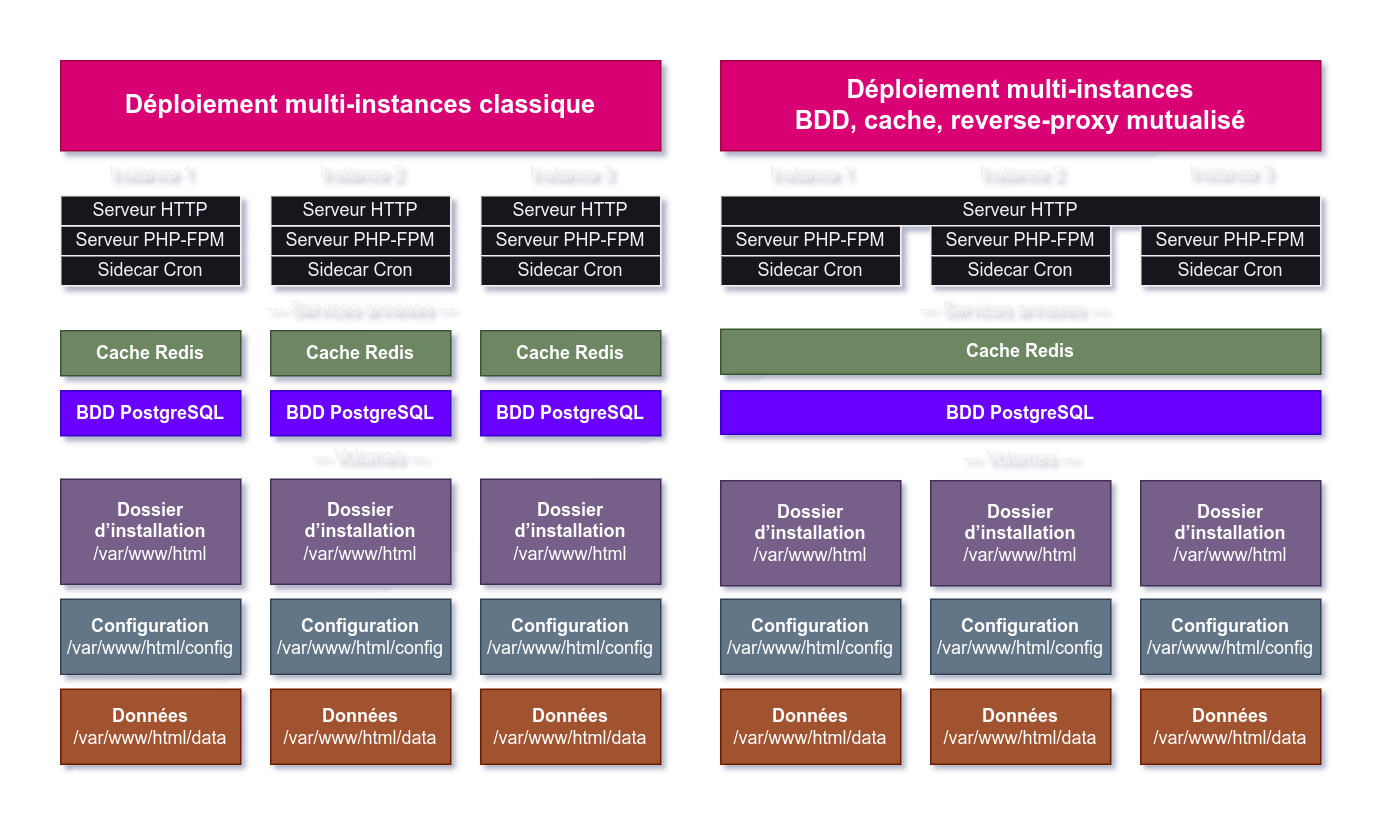
The installation on the left is fairly typical of a multi-instance deployment in virtual machines.
For three Nextcloud instances, there are three instance-specific services: the HTTP server, the PHP-FPM server and the Cron sidecar. Sometimes, the three services are merged into one, especially when using the Nextcloud apache image and the webcron… but this has a major impact on Nextcloud performance.
With this, we also have two additional services which are not specific to Nextcloud but on which Nextcloud depends: the PostgreSQL database and the Redis cache (the latter is optional but greatly improves performance).
Next, each instance will have three volumes :
- the installation folder, mounted on
/var/www/html/, which contains Nextcloud’s system files and weighs around 1 GB ; - the lightweight configuration folder, mounted on
/var/www/html/config/; - the data folder on
/var/www/html/data/.
And finally, not listed here, but other auxiliary services may be required:
- the Collabora Office server (or Onlyoffice) for collaborative editing of Office documents;
- the TURN/STUN server to use Nextcloud Talk ;
- an Imaginary server to generate thumbnails ;
- other third-party services.
As you can see, this leads us to maintain a very substantial number of services per instance.
For our part, we’re starting from the installation on the right, which is still fairly common, by mutualizing certain resources:
- the database and cache are shared ;
- our reverse-proxy Caddy is shared by all our services and serves files directly from the Nextcloud instance.
But this level of mutualization is not yet sufficient for our taste, as soon as we want to host several Nextcloud instances.
🔗Data
S3 makes this part very simple: we can create one bucket per instance and store data inside. Thus, the data volume disappears and is replaced by an additional service, Garage, accessible over the network.
🔗The installation folder
The installation folder is the volume in which Nextcloud stores its system files: its components, its plugins… all the “heart” of Nextcloud is kept inside. The files stored inside don’t move unless Nextcloud or its plugins are updated.
So, for three Nextcloud instances of the same version and with the same plugins, the installation folder will be identical. This is interesting, because it means there’s a way to mutualize this resource between instances. It’s even more interesting to share this folder since it weighs in at 1.2 GB per instance.
Unfortunately, Nextcloud doesn’t like the idea at all: every time it starts up, it performs a few disturbing operations:
- it uses a file to lock the folder for writing and will refuse to start up if this lock file is present, meaning that another instance is using it;
- it attempts to update the files in this folder if it detects that an update is available… but this will necessarily impact other instances.
So we patched the Nextcloud startup script to disable all Nextcloud interactions with this folder.
This gives us the following configuration:
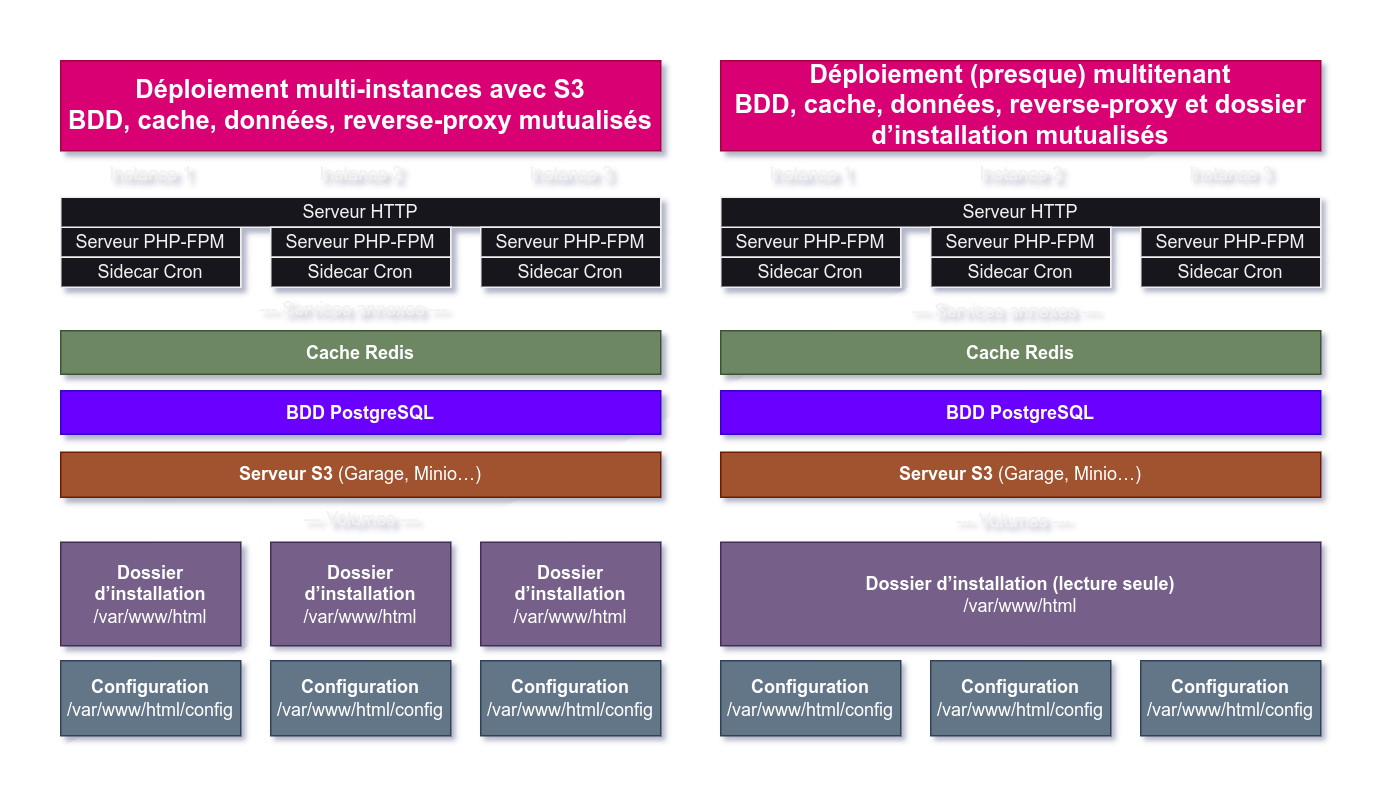
Left: installation without sharing the installation folder. On the right, our final configuration.
We still have a few areas for improvement:
- to avoid all cron of our Nextcloud instances occurring at the same time and overloading the server, we could see to what extent we can reuse Chronos, used by Framaspace to create a “cron queue”, for this purpose;
- we could theoretically use a single instance of PHP-FPM by changing the configuration folder according to the host name as Framaspace does (as shown in their video), and thus achieve a truly multi-tenant installation ;
- we need an Imaginary server instance to offload the PHP server on thumbnails generation ;
- we will likely need a patched Collabora instance at some point.
Note that our installation folder is mounted read-only on our instances.
🔗Configuration
Finally, all that’s left is the configuration volume, which contains less than 5 Kb of files… which we haven’t yet managed to relocate. But as it’s a very small volume, it’s not a big deal.
On the other hand, we need to add a few parameters so that our tweaking of the installation folder doesn’t cause any problems:
- updatechecker’ => false,` to disable checking for new updates (we’ll take care of that ourselves);
- appstoreenabled’ => false,` to disable installation and updating of applications via the Nextcloud store.
For the rest of the configuration, we’ll use the environment variables to provision a new installation with the desired configuration:
POSTGRES_*to configure a new database;SMTP_*andMAIL_*to configure e-mail sending;OBJECTSTORE_S3_*for data storage;NEXTCLOUD_TRUSTED_DOMAINSandTRUSTED_PROXIESfor the reverse-proxy and hostname configuration;REDIS_HOST_*for the Redis cache;NEXTCLOUD_ADMIN_*to create an administration account;NEXTCLOUD_UPDATE=0to disable Nextcloud update at startup;NEXTCLOUD_DATA_DIR=/dataas a fake data volume to which we add a.ocdatafile. As the data is stored in the S3 bucket, the data folder is of no use to us.
🔗Plugins
We add and configure two additional applications to Nextcloud:
- the Collabora Office app for collaborative document editing;
- the OpenID Connect app to connect Nextcloud to our authentication provider.
🔗Maintenance
Now that we have a complete installation, let’s see how we can simply add a new instance and update applications.
To deploy a new instance: we use an ephemeral Nextcloud container to initialize the configuration folder, the S3 bucket and the database; it uses the official image (and not our patched image), so it will perform the entire initialization and update process. Once initialized, we stop the container and add the new instance to our Nextcloud cluster with the other instances we host, on our Core repository.
To perform a Nextcloud or application update: we switch all instances to maintenance mode, then use an ephemeral container that uses the official image to update the Nextcloud installation folder, which is mounted as read-write on this container. This procedure updates all instances simultaneously. Once the update is complete, we use the command ./occ upgrade on each instance to update each of the databases, then deactivate maintenance mode.
🔗The Paheko factory
For Paheko, free accounting and membership management software, the process is a little easier but required a lot of preparation. The software natively supports multi-tenant installations, but we had to do a lot of fiddling: Paheko provides a specific configuration file for this kind of installation, and the usual scripts (for crons, emails) are different from a usual installation.
In short: it’s supported, but you’ll have to graft the necessary modules yourself, and probably touch up the PHP code a bit.
We’ve created a Docker image for Paheko which has several advantages over a conventional installation:
- the instance is designed to be multi-site, so there’s no need for fiddling ;
- domain names are fully customizable: with the configuration file supplied, it was only possible to create sub-domains (e.g.: myorg.paheko.cloud…).
- we use a PHP-FPM alpine image rather than an Apache server, enabling us to serve Paheko with our Caddy reverse-proxy in HTTP/3 without passing through an intermediary HTTP server, and offering performance gains;
- native integration of system crons;
- the container is not privileged, nothing runs as root (not even cron or PHP-FPM server);
- our image supports mass e-mailing and bounces management (e-mails returned to sender);
- configuration can be provisioned with environment variables.

🔗SSO configuration
Paheko allows the software to be used with an SSO, but this does not mean that the software supports an SSO. A wiki page is dedicated to this.
To put it simply: you have to write your own SSO integration in PHP. This isn’t easy or accessible, and we didn’t have much time to devote to it, so we opted for another choice: using a generic admin account. Everyone who has been granted access to their organization’s accounting instance is therefore admin.
This means there is no nominative history of actions, which is still rather problematic for accounting purposes, but we live with this compromise.
True SSO management is actually handled by the caddy-security plugin, which we use as an OIDC authentication wall, and which checks whether the user has the right roles to access the accounting system. Finally, we don’t use Paheko at all to manage OIDC.
🔗Paheko’s shortcomings
Paheko has the advantage of being very light and efficient in terms of resource consumption (absolutely nothing to do with Nextcloud). A single instance of the software can host several organizations without a hitch.
There are, however, several notable drawbacks:
Paheko only supports SQLite. This does not pose any performance problems, but makes it difficult to conceive a highly available / distributed installation on several servers. The volume containing user data can quickly weigh several GB, and synchronizing it in real time from one server to another can prove complicated as we wrote above.
Paheko does not support the S3 protocol. Files (and in particular accounting attachments) are either integrated into the SQLite database (which won’t make it lighter…), or managed on the host’s file system. This brings us to the same constraints as above: it’s hard to imagine a highly available server in this configuration.
Third-party authentication sources are not well integrated. As we wrote above, integrating an SSO is more a matter of tinkering than software integration, and has led us to make compromises.
These weaknesses are offset by the simplicity of data storage and maintenance management: Paheko relies on a rather “old-school” (monolithic) management of storage space and data, but everything rests in a single volume. Even if you have to host 50 organizations, there will always be only one volume to back up. This is a far cry from the headache of hosting a Nextcloud cluster.
Updating all Paheko instances remains extremely simple: on our side, all we have to do is change the version number and regenerate our Docker image, and the instances will update themselves in turn the next time their users visit. Beware, however, of updates that break the installation; fortunately, the changelog is well written.
To create a new instance, nothing could be simpler: just create a folder with the domain name of the new instance in the Paheko volume, folder users/. We then configure the caddy-security module for SSO management.
🔗The WordPress factory
WordPress (https://wordpress.org/) is the world’s most widely used web design software (no less), and it’s free (yay).
Thanks to its maturity, WordPress has long included Multisite functionality for setting up a multi-tenant instance.
Because WordPress is so widespread, it’s particularly dangerous to host, as any security vulnerability found is quickly exploited. Having a Multisite instance greatly simplifies maintenance: instead of having to update each instance individually, we can simply keep the single Multisite instance up to date.
Another great advantage of this configuration is that the Multisite functionality is really designed to simplify the deployment of a new site with just one click. It’s even simpler than with Paheko, since it can be done via the web interface.
However, this environment comes with its own set of disadvantages.
🔗The disadvantages of Multisite installation
Plugin and themes locked. For our users, it’s not possible to install new themes or custom plugins. Given that most of the security flaws in WordPress come from plugins, this should be seen as an advantage… but it’s still a constraint. As for themes, we have pre-installed about thirty popular themes, and if the organizations we host want a particular theme, they can ask us to install it.
One security flaw compromises all websites. If a security flaw is discovered in one of our hosted sites, it’s quite likely that the other sites will also be compromised.
Traffic surges: if one of the hosted sites has a traffic peak, the other sites will be slowed down too.
Everything rests on one instance. If the Multisite instance goes down, all the sites go down with it.
We’re now going to show you the workarounds we’ve found to avoid these inconveniences.
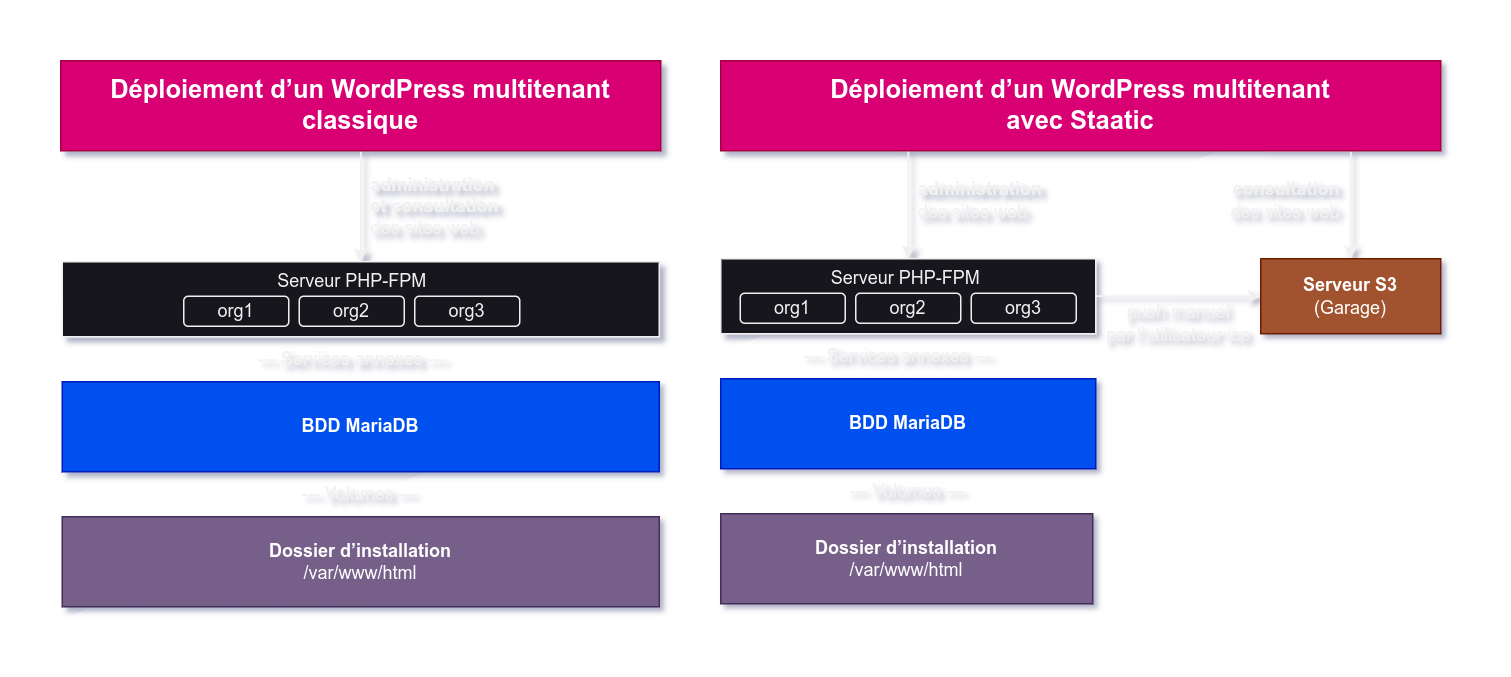
🔗Staatic to counter the disadvantages
Staatic is a WordPress plugin that lets you create a static site from a WordPress site. It works by indexing the website and then uploading it to the desired storage medium (S3, local folder, FTP, GitHub Pages…). We have naturally chosen S3 as the destination medium.
Publishing a site is triggered manually, by pressing a “Publish” button in a website’s administration interface; the WordPress site itself then becomes a pre-production space for our users before sending the site to the S3 bucket.
Our S3 server, Garage, can be configured to serve the content of an S3 bucket via HTTP without authentication. Our blog (this very website) and our our documentation is served that way; in parallel, it duplicates in real time the websites it hosts on three different servers, enabling traffic load balancing if required.
So, in the event of a failure of the WordPress multisite instance, the site administration space will be unavailable, but nothing else will move: sites will remain online, since they are hosted on Garage.
Furthermore, static sites are inherently much faster than classic WordPress sites. HTML pages are served directly, without being processed by a PHP server.
And finally, in terms of security: there’s no need to expose the WordPress instance itself, since it’s simply used to design the site, not to serve it directly to the people who are going to consult it. We can therefore set up an authentication wall across the entire WordPress instance.
The only major drawback of this configuration is the impossibility of hosting dynamic content on the site. No contact form, reservation plugin, or other potentially interesting uses: it’s fine for a showcase site or a blog, but you quickly reach its limits. But it also simplifies maintenance and drastically reduces the attack surface: it’s the best compromise we’ve found.
Of course, as part of our web hosting package, we’ll also offer to host a raw S3 bucket, without WordPress, to serve a static site for geeks who know how; but that doesn’t concern the majority of the audience we’re aiming to reach.
🔗Other software in our stack
We’ve covered the three softwares for which we’ve achieved the best results after several months’ work, but we’ve also improved other aspects of our software infrastructure that we’d like to introduce to you.
🔗Listmonk
We are fortunate to be able to take immediate advantage of the new version of Listmonk, which now supports multi-user usage and integrates OpenID Connect. The software is used to send newsletters, which Paheko already allows, but the uses may vary.
Listmonk also supports an S3 backend for hosting e-mail attachments.
🔗MX secondary and newsletters
By tweaking a new instance of docker-mailserver, which we’ve been using for 6 years to host our e-mails, we’ve set up a secondary mail server that can receive e-mails if the main instance goes down.
This instance is hosted on a dedicated server (stanley).
This secondary server is used by Paheko and Listmonk to send mass e-mails, rather than our main server: indeed, sending mass e-mails immediately causes a slowdown in e-mail distribution due to rate limits imposed by the giants (in particular Google).
So, to prevent all our members’ mailboxes from being temporarily blocked (for several hours!) by Google, we use this secondary server which will be subject to the rate limit instead of our main server.
For the same reason, earlier this year, we were forced to limit the usage of our mail service to prevent associations from using it to send emails to dozens of people at the same time (which led to delays in distribution), and to encourage them to use a newsletter service for this purpose, whether ours or elsewhere, with the sole aim of ensuring the proper distribution of correspondence from our members.
🔗Domain name management
To simplify the work of some of the organizations we support, we sometimes intervene directly on the domain names of organizations that have given us their consent.
For the time being, we use HappyDomain to manage their DNS zones. HappyDomain works by retrieving API rights from registrars and supports many providers… But this software is not very mature, contains bugs and seems poorly maintained, which encourages us to look for alternatives.
🔗Internal supervision
We reworked our internal supervision this year: we left Netdata, which is changing its license and now incorporates pieces of proprietary code, and migrated to a Telegraf + InfluxDB + Grafana stack. This stack is working perfectly so far.
Alex, a member of our Contribution Committee, held a conference on the subject at the Capitole du Libre 2024.
🔗Mail service
We’ve considerably improved our mail service this year, partly through the integration of our secondary MX mentioned above, and partly through the addition of a new webmail that runs on Roundcube.
We’ve still got a nice present in store for our members for next year: Hannaeko and Neil are working on a new software brick that will replace the interface we use today to add aliases and mailboxes with a new, updated piece of software that will use OpenID Connect to authenticate members.
We also hope that this project can be used by developers and users of docker-mailserver as an API and frontend for using the service.
🔗CI/CD and Docker images
Finally, in the last big news of the year, we’re using one of our new Beta servers (monacha) to run CI/CDs on our repositories using the Gitea-forked runner act.
This new tool allows us to automatically deploy this website, our documentation, and also recompiles our binaries including (rs-short, autodiscover or constello with each new commit on the main branch. It generates a Docker image for each of these software packages, which are hosted on our forge.
This greatly simplifies update deployments: gone are the days when we compiled production binaries on our computers! We now have a server for that.
🔗What’s next?
To conclude this series of three lengthy articles (over an hour’s reading in total?!) on technical improvements at La Contre-Voie, here’s our plan for the year ahead.
🔗Expand
First of all, we’re going to continue expanding our service offering as we’ve previously announced: we’re going to use all these new servers to host our new tools, starting with the a la carte services (including PeerTube, which isn’t up and running yet), then adding the free of charge services (under registration) that we’d like to make available to you.
At that point, we’ll (finally!) migrate our old member service to our new SSO after completing the various technical prerequisites for this migration (captcha development, membership management in Keycloak, deployment of the new mail service interface and integration of our historical Git and Nextcloud services).
On this basis, we will build a free-to-use service offering (financed by your donations and our other actions), unified and requiring only the creation of an account on our SSO.
🔗Consolidate
Next, we’ll be working on the finishing touches to this service offering adding the missing cogs. In bulk: writing a membership management tool for us, developing a rights management tool so that our beneficiary organizations can administer their teams, writing configurations to improve supervision of our services, contributing to tools we use…
We’ll also take some time to take stock of our previous service offering, in place since 2019: what to do with sncf, the tool behind our Forms service, which we no longer have the time to maintain? What direction should we take for our Draw service, which is really little used, or our Links service, which regularly hosts phishing links and costs us moderation time? We’ll take the time to take a step back and adapt our trajectory accordingly.
Finally, this consolidation will also take place behind the scenes: we’ll be reviewing the distribution of these services across our various servers to create real-time data redundancy, guard more effectively against the risks of hard disk failure, automate update and maintenance processes, take the time to do things right even if it means slowing down a little.
The work of consolidation is rather unrewarding (we don’t launch a new service, it’s maintenance) and rather invisible (we won’t announce that we’re maintaining a service, it’s what’s expected of us, it’s considered a due), and yet it’s an absolutely essential step.
🔗Documenting
In parallel with this consolidation work, we will continue to document and explain our approach, on our documentation as much as on this blog (although our publications are quite irregular…), to spread our knowledge as widely as possible, throughout the transformation of our services.
Last year, we had already devoted a lot of time to our documentation platform, and we will continue to enrich it over time.
🔗… if we manage to exist
There are only a dozen of us, with one full-time volunteer who has been with us for 6 years - and who can’t stay just a volunteer for much longer.
Three years ago, we were still starting with a annual budget of €2,000, and yet today we still persist in the idea that we can crank up the speed and start paying a salary, to help as many people as possible evolve their digital practices.
We don’t yet know whether we’ll have the financial means to reach the €12,000 goal of our donation campaign which, if supplemented by membership fees, grants, paid educational interventions, hosting services and other sources, will perhaps give us the capacity to pay a full-time SMIC.
Would you like to support us in achieving this?
If you’ve enjoyed reading these articles, if you think it’s worth a try, if you’d like to read us again, then you can make a donation:
It’s thanks to you that we’re where we are. Thank you for your support, and see you next week for another article, less technical this time!